Before the web, Tim Berners-Lee wrote an application called ENQUIRE. It was based around cards that show the links between information in a database, allowing the user to move between the relational links as they research a subject.
“When I first began tinkering with a software program that eventually gave rise to the idea of the World Wide Web, I named it Enquire, short for Enquire Within upon Everything, a musty old book of Victorian advice I noticed as a child in my parents’ house outside London. With its title of suggestive magic, the book served as a portal to a world of information, everything from how to remove clothing stains to tips on investing money.”
ENQUIRE was limited to linking between specific databases of knowledge, so Berners-Lee abandoned it and moved on to develop a network that would allow linking across the boundaries of specific databases - the World Wide Web.
When we develop a new technology, the names and metaphors we use to describe them are critical. ENQUIRE was influenced by a book that claimed to be an oracle - to have the answer for every question, to promise the ‘suggestive magic’ that so excited the young Berners-Lee. But that promise was ultimately unfulfilled. Berners-Lee recognised that what he needed to build was not an oracle but a map - a web of paths and connections linking information and guiding users as they research, not an all-knowing entity that gives us a single answer.
The current frenzied debate about Large Language Models and Artificial Intelligence is partly because tools like ChatGPT look, on the surface at least, like oracles. We type in questions, enquiring within upon anything, and get something that looks remarkably like an answer. But what if these new technologies aren’t oracles, but a new kind of map?
The metaphors we use to describe LLMs and AI now are critically important. If we anthropomorphise them, and think of them as conscious, it will be almost impossible to not consider them as oracles. We will worry about them replacing humans in various tasks, worry about whether they are telling us the truth, and look for ways to regulate the ‘suggestive magic’ they seem to posses.
We’re making this assumption because the most uncanny version of these technologies are using conversational interfaces as their mode of interaction. There was a spike of interest in conversational interfaces a few years ago, as voice technologies like Alexa and Siri entered our lives. The difference between screen-based search and voice based search is the difference between a map and an oracle - on screens we’re given a list of search results to navigate, whilst in voice based search we’re not read a list of potential links - we’re given an answer.
When you are trying to build an oracle, you have an incredible responsibility to ensure that this answer is right. I was at a workshop with a UK Health Charity a few years ago in which someone from the NHS said that they had been approached by one of the big tech companies, asking if they could use their database to provide answers for their voice interface. If the oracle gives you the wrong answer when you’re looking for a movie recommendation, that’s annoying. When you’re asking for medical advice, it’s potentially harmful.
Most search engines generate their results using a map called a ‘knowledge graph’. This is a map of connections between objects that not only knows how these objects are connected to each other, but also knows what those connections mean. In 2007, Danny Hillis built Freebase, a knowledge graph that scraped data from the emerging networks of web 2.0, mapping the different types of connections between them. By encoding these types of connection within the data, it meant that search engines could do some of the work that users had previously had to do in deciding what result was the best answer. Hillis described it as a “digital almanac”, and web 2.0 entrepreneur Tim O’Reilly called it “like a system for building the synapses for the global brain.”
Metaweb, the company that built Freebase, was acquired by Google in 2010. As part of the deal, Hillis required Google to keep the knowledge graph public via an API for at least 5 years. In 2015, Google shut down the Freebase API and launched their own Knowledge Base that now runs the ‘knowledge panel’ you see on Google search results.
A couple of years ago, my company, Storythings, did a bit of comms work with MIT Knowledge Futures Group, where Danny Hillis and SJ Klein are working on a new version of Freebase called The Underlay. This updated version is based not just on helping machines understand the links between things, and what those links mean, but also the context of those links - who created them, and whether the links are reliable. The Underlay is designed to enable the dynamic presentation of these concepts and their relationship, a dynamic map of the ever changing relationships between facts. It’s not an oracle of knowledge, but a map of how we produce knowledge:
“The Underlay will gather knowledge currently used to produce publications, databases, and dynamically generated displays. It will make each associated assertion available in a machine-readable form that can be dynamically searched, vetted, and combined, based on its provenance. By connecting multiple sources together, each asserted claim can be analyzed for relevance and veracity, recombined and re-presented for different purposes. The Underlay will allow intelligent software to help people find what is relevant and judge what is true.”
The discussions around LLMs at the moment are mostly framing them as oracles. The hallucinatory conversations journalists are having with ChatGPT make it very hard to not anthropomorphise the technology, to see them as oracles, not maps.
But the best metaphor I’ve seen for LLMs, the one that has really helped me understand what they actually do, is a lot more like a map than an oracle. In his newsletter Humane Ingenuity, Dan Cohen, the Dean of NWU and academic on digital media and humanities, describes the output of an LLM as not a single truth, but a path taken across a topological map:
“a simple LLM has the same issue a pool table has: the ball will always follow the same path across the surface, in a predictable route, given its initial direction, thrust, and spin. Without additional interventions, an LLM will select the most common word that follows the prior word, based on its predetermined internal calculus. This is, of course, a recipe for unvaried familiarity, as the angle of the human prompt, like the pool cue, can overdetermine the flow that ensues.
To counteract this criticism and achieve some level of variation while maintaining comprehensibility, ChatGPT and other LLM-based tools turn up the "temperature," an internal variable, increasing it from 0, which produces perfect fidelity to the physics, i.e., always selecting the most likely next word, to something more like 0.8, which slightly weakens the gravitational pull in its textspace, so that less common words will be chosen more frequently. This, in turn, bends the overall path of words in new directions. The intentional warping of the topological surface via the temperature dial enables LLMs to spit out different texts based on the same prompt, effectively giving the snowball constant tugs in more random directions than the perfect slalom course determined by the iron laws of physics. Turn the temperature up further and even wilder things can happen.”
I love the metaphor of the pool table - writing a prompt for an LLM is like pulling back the pool cue before you take a shot. You get to decide the spin, angle and power, and then the ball that represents your prompt ricochets around the topological surface of the knowledge space within the LLM, finding the optimal path that ends up shaping it’s response.
Just like the Underlay, LLMs are dynamic, and can be made ‘weird’ by changing the parameters used to shape the topological space your prompt ricochets around. This is what made me realise that they are maps not oracles. The hallucinatory responses in ChatGPT are not answers - they are paths within a multidimensional space of knowledge, helping us map out those spaces and understand its hills and valleys.
The reason we don’t immediately recognise these tools as maps is partly because of the conversational interface, but also because the spaces within LLM are multi-dimensional. They’re not 2D or 3D spaces, but have 1000s of dimensions, and are incredibly hard for us to conceptualise as spaces. They create each new path anew, testing each step against the unimaginably complex probabilistic space of the corpus of knowledge they are trained on. They are maps of places that we can’t comprehend, and that is why we haven’t originally understood them as maps.
It’s also why ChatGPT stumbles on the kinds of truths that the Underlay is designed to resolve. If the topologies of the knowledge it is based on tends towards a certain path, that doesn’t automatically mean that the path is the correct one. The answer that it thinks is right is the one that looks like the most trodden path within the forest of knowledge it has access to.
This is why these new tools are best at mapping spaces that our previous tools haven’t been able to map. LLMs map the contours of massive corpuses of knowledge in a way that can reveal biases and structures in really interesting ways. In his New Yorker essay, sci-fi writer Ted Chiang described LLMs as a “blurry JPEG of the web”, in a way that was intended to be critical. But this looks at the problem from the wrong way round. LLMs optimal use is not to see things that we can already see clearly in a new way, but to bring into focus questions that we’ve never been able to ask before. It’s like the difference between the Hubble and the James Webb telescope - it’s best at bringing really fuzzy spaces into a bit more resolution.
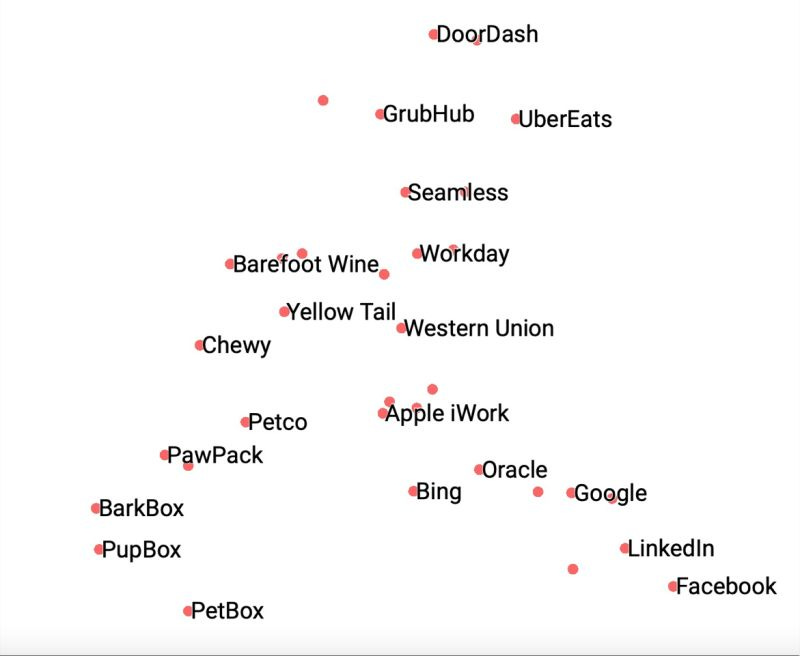
The best illustration of this I’ve seen is Noah Brier’s BrXnd.ai project. Brier started with a simple toy called Collxbs that used ChatGPT and image AI DALLE2 to generate fictional images and text descriptions of fictional collaborations between brands. Brier was using the technologies to do what they do best - hallucinate imaginary answers that can only be produced by ricocheting prompts around the corpus of data the LLMs had about the brands.
But as he saw the outcome of prompts, he noticed that some brands had stronger presences in the fictional collabs than others. It was as if the LLM was intuiting something about the strength of those brands, about how much presence and power they had in the data the LLMs were trained on:
“Because it has a general sense of concepts from its gigantic corpus, it can group brands in meaningful ways without any other inputs. The image below is a two-dimensional analysis (I did a 3d one as well) of a bunch of brands that various friends asked me to include (hence the random assortment). What’s surprising about the image is how unsurprising it is. The model seems to have an intuitive understanding of categories when given nothing more than the brand’s name and some indicator that it’s a brand. (I do that so when I ask for Apple, for instance, I get the technology company instead of the fruit.) Since it seems basically correct, it also raises other interesting questions, like why has it grouped Western Union as the closest non-wine brand to Yellow Tail? Or what puts Google closer to consumer brands than Facebook?”
There has been decades of theories about how brands work - how the strength and recognition of a product’s brand has an influence on the purchasing decision of the audience. But the picture has always been fuzzy, relying on audience surveys and market research that might prove correlation, but not causation.
Brier is using ChatGPT to bring a fuzzy answer into a bit more focus, in the way that only LLMs can do. It’s a bit like doing audience research in a multidimensional space with millions of contributors all at once. Brier is mapping a space in a way that’s never been possible before.
Maybe this is what LLMs can do best - map knowledge spaces to reveal their biases and assumptions. One of the things I’ve loved about LLMs is the creativity they’ve opened up in development communities - people are playing and testing the boundaries of these new tools in incredibly creative ways.
I see this work not just as technological exploration, but as a kind of media literacy. By testing the boundaries of their abilities and weaknesses, we’re beginning to understand what kind of maps they are, and what kinds of things we can use them to understand. This feels really exciting to me, way more exciting than the idea that they are oracles that can replace human thought.
The internet has never been an oracle, and the answers we can find have always been, and will always be, fuzzy. We are, again, building a new kind of map, one that, like the World Wide Web and Freebase before it, will give us new ways to understand, produce, and share knowledge. The people building new interfaces for these tools need to understand that, and help us see them as maps, not oracles.
Very thought provoking piece. “The map is not the territory” quote leaps to mind. That made me dig a bit deeper into that quote actually means and I didn't use ai to find it. I used search. I am finding that I toggle back and forth between the approaches...as I continue to try and understand the why and whats.
This quote comes from Alfred Korzybski, father of general semantics: “A map is not the territory it represents, but if correct, it has a similar structure to the territory, which accounts for its usefulness”. To sum up, our perception of reality is not reality itself but our own version of it, or our own “map”.
Really insightful. Seeing exploration of the knowledge territory as maps and routes also makes it easier to think about the ethical side of things. Which (whose…) knowledge is excluded from the territory being mapped, what are the implications of omitting parts of the territory in sparse LLMs etc. (e.g. a Russian language LLM that only uses Russian sources might be more “efficient” in terms of computing power/cost, but the maps would change significantly). Or, for LLMs that self-train, what happens to our maps when more of the territory is self-generated than not… Roll on the improbability drive!




Very thought provoking piece. “The map is not the territory” quote leaps to mind. That made me dig a bit deeper into that quote actually means and I didn't use ai to find it. I used search. I am finding that I toggle back and forth between the approaches...as I continue to try and understand the why and whats.
This quote comes from Alfred Korzybski, father of general semantics: “A map is not the territory it represents, but if correct, it has a similar structure to the territory, which accounts for its usefulness”. To sum up, our perception of reality is not reality itself but our own version of it, or our own “map”.
Really insightful. Seeing exploration of the knowledge territory as maps and routes also makes it easier to think about the ethical side of things. Which (whose…) knowledge is excluded from the territory being mapped, what are the implications of omitting parts of the territory in sparse LLMs etc. (e.g. a Russian language LLM that only uses Russian sources might be more “efficient” in terms of computing power/cost, but the maps would change significantly). Or, for LLMs that self-train, what happens to our maps when more of the territory is self-generated than not… Roll on the improbability drive!